[TOC]
1.容器的重要特征
随着互联网和软件技术的发展,容器技术越来越为大家所熟知和使用,那么容器技术到底好在哪里呢? 主要是他有如下四个重要特征:
隔离性:基于Linux kernel提供的 namespace资源隔离方案。
安全性:资源隔离,资源访问自然受到了严格的限制,因此同时也把安全问题解决了
便捷性:相对于虚拟机技术,容器技术启动速度非常快
可配额:基于Linux 的Cgroups 即:Control Groups,可以对一个或一组资源控制和监控
docker优势
- 资源利用率高
- 启动快
- 运行环境一致
- 便于持续交付和部署
- 便于迁移
- 便于维护和扩展
-
docker劣势
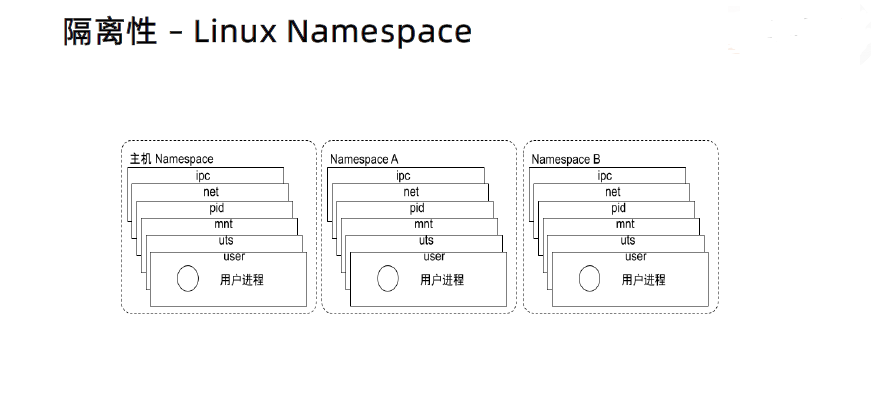
2 Linux namespace
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。提供了对UTS、IPC、mount、PID、network、User等的隔离机制。
| 分类 | 系统调用参数 | 相关内核版本 | 隔离内容 |
|---|---|---|---|
| Mount namespaces | CLONE_NEWNS | Linux 2.4.19 | 挂载点(文件系统) |
| UTS namespaces | CLONE_NEWUTS | Linux 2.6.19 | 主机名与域名,影响uname(hostname, domainname) |
| IPC namespaces | CLONE_NEWIPC | Linux 2.6.19 | 信号量、消息队列和共享内存, inter-process communication,有全局id |
| PID namespaces | CLONE_NEWPID | Linux 2.6.24 | 进程编号 |
| Network namespaces | CLONE_NEWNET | Linux 2.6.29 | 网络设备、网络栈、端口等等 |
| User namespaces | CLONE_NEWUSER | Linux 3.8 | 用户和用户组 |
三个系统调用
| 调用 | 作用 |
|---|---|
| clone() | 实现线程的系统调用,用来创建一个新的进程,并可以通过设计上述参数达到隔离。 创建时传入 flags参数,可选值有 CLONE_NEWIPC, CLONE_NEWNET, CLONE_NEWNS, CLONE_NEWPID, CLONE_NEWUTS, CLONE_NEWUSER, 分别对应上面六种namespace。 |
| unshare() | 使某进程脱离某个namespace |
| setns() | 把某进程加入到某个namespace |
常用操作
-
查看当前系统的Namespace
lsns -t <type>
-
查看某进程的Namespace
ls -la /proc/<pid>/ns/
-
进入某Namespace运行命令
nsenter -t <pid> -n ip addr
root@dell:~# unshare --help
Options:
-n, --net[=<file>] unshare network namespace
-f, --fork fork before launching <program>
..
root@dell:~# unshare -fn sleep 60
# another terminal
(base) dell@dell:~$ sudo su -
root@dell:~# ps aux |grep sleep
root 7280 0.0 0.0 16308 756 pts/1 S+ 18:16 0:00 unshare -fn sleep 60
root 7281 0.0 0.0 16320 792 pts/1 S+ 18:16 0:00 sleep 60
root@dell:~# lsns -t net
NS TYPE NPROCS PID USER COMMAND
4026532008 net 595 1 root /sbin/init splash
4026532545 net 2 7280 root unshare -fn sleep 60
4026532636 net 1 2841 rtkit /usr/lib/rtkit/rtkit-daemon
# 新的Namespace里面 network信息
root@dell:~# nsenter -t 7280 -n ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# 主机network信息
root@dell:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: enp0s25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether f8:b1:56:c0:e2:a5 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.4/24 brd 192.168.1.255 scope global dynamic noprefixroute enp0s25
valid_lft 604134sec preferred_lft 604134sec
docker example
root@dell:~# docker run -itd --name nginx nginx:1.19.10
8db4d89be717eddefb5f0253a89f0b23f27f7c6a96c9dd3feea896ccd5097af3
root@dell:~# docker exec -it nginx bash
容器中查看Namespace
root@8db4d89be717:/# lsns
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 3 1 root nginx: master process nginx -g daemon off;
4026531837 user 3 1 root nginx: master process nginx -g daemon off;
4026532546 mnt 3 1 root nginx: master process nginx -g daemon off;
4026532547 uts 3 1 root nginx: master process nginx -g daemon off;
4026532548 ipc 3 1 root nginx: master process nginx -g daemon off;
4026532549 pid 3 1 root nginx: master process nginx -g daemon off;
4026532551 net 3 1 root nginx: master process nginx -g daemon off;
exit
# 主机上查看Namespace
root@dell:/proc/89/ns# lsns
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 603 1 root /sbin/init splash
4026531836 pid 602 1 root /sbin/init splash
...
4026532546 mnt 2 13562 root nginx: master process nginx -g daemon off;
4026532547 uts 2 13562 root nginx: master process nginx -g daemon off;
4026532548 ipc 2 13562 root nginx: master process nginx -g daemon off;
4026532549 pid 2 13562 root nginx: master process nginx -g daemon off;
4026532551 net 2 13562 root nginx: master process nginx -g daemon off;
root@dell:/proc/89/ns# cd /proc/13562/ns/
root@dell:/proc/13562/ns# ls -l
total 0
lrwxrwxrwx 1 root root 0 Jan 1 18:36 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Jan 1 18:36 ipc -> 'ipc:[4026532548]'
lrwxrwxrwx 1 root root 0 Jan 1 18:36 mnt -> 'mnt:[4026532546]'
lrwxrwxrwx 1 root root 0 Jan 1 18:36 net -> 'net:[4026532551]'
lrwxrwxrwx 1 root root 0 Jan 1 18:36 pid -> 'pid:[4026532549]'
lrwxrwxrwx 1 root root 0 Jan 1 18:37 pid_for_children -> 'pid:[4026532549]'
lrwxrwxrwx 1 root root 0 Jan 1 18:36 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Jan 1 18:36 uts -> 'uts:[4026532547]'
root@dell:~# docker inspect nginx|grep -i pid
"Pid": 13562,
"PidMode": "",
"PidsLimit": null,
3 Linux Cgroups
Cgroups最初的目标是为资源管理提供的一个统一的框架,既整合现有的cpuset等子系统,也为未来开发新的子系统提供接口。现在的cgroups适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization)。Cgroups提供了一下功能: 1.限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。 2.进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。 3.记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间 4.进程组隔离(isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。 5.进程组控制(control)。比如:使用freezer子系统可以将进程组挂起和恢复。
通过mount -t cgroup 命令或进入 /sys/fs/cgroup 目录,我们看到目录中有若干个子目录,我们可以认为这些都是受 cgroups 控制的资源以及这些资源的信息。
- blkio: — 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
- cpu — 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
- cpuacct — 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
- cpuset — 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
- devices — 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
- freezer — 这个子系统挂起或者恢复 cgroup 中的任务。
- memory — 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成内存资源使用报告。
- net_cls — 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
- net_prio — 这个子系统用来设计网络流量的优先级
- hugetlb — 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
cpu example
root@u18-01:~# while [ True ];do
> x=$x+1
> done;
# 查看cpu使用情况
root@u18-01:~# top
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5028 root 20 0 32308 15996 3504 R 100.0 0.1 1:20.16 bash
# 添加CPU资源限制
root@u18-01:~# echo 50000 > /sys/fs/cgroup/cpu/mydemo/cpu.cfs_quota_us
root@u18-01:~# echo 5028 > /sys/fs/cgroup/cpu/mydemo/tasks
root@u18-01:~# top
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5028 root 20 0 32472 16148 3504 R 49.7 0.1 1:41.24 bash
memery example
root@u18:~# cat malloc.c
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define BLOCK_SIZE (100*1024*1024)
char* allocMemory() {
char* out = (char*)malloc(BLOCK_SIZE);
memset(out, 'A', BLOCK_SIZE);
return out;
root@u18:~# cat main.go
package main
//#cgo LDFLAGS:
//char* allocMemory();
import "C"
import (
"fmt"
"time"
)
func main() {
// only loop 10 times to avoid exhausting the host memory
holder := []*C.char{}
for i := 1; i <= 20; i++ {
fmt.Printf("Allocating %dMb memory, raw memory is %d\n", i*100, i*100*1024*1025)
// hold the memory, otherwise it will be freed by GC
holder = append(holder, (*C.char)(C.allocMemory()))
time.Sleep(time.Second*5)
}
time.Sleep(time.Hour)
}
root@u18:~# CGO_ENABLED=1 GOOS=linux CGO_LDFLAGS="-static" go build
root@u18:~# ./malloc
Allocating 100Mb memory, raw memory is 104960000
Allocating 200Mb memory, raw memory is 209920000
Allocating 300Mb memory, raw memory is 314880000
Allocating 400Mb memory, raw memory is 419840000
Allocating 500Mb memory, raw memory is 524800000
Allocating 600Mb memory, raw memory is 629760000
Allocating 700Mb memory, raw memory is 734720000
Allocating 800Mb memory, raw memory is 839680000
Allocating 900Mb memory, raw memory is 944640000
Allocating 1000Mb memory, raw memory is 1049600000
Allocating 1100Mb memory, raw memory is 1154560000
Allocating 1200Mb memory, raw memory is 1259520000
Killed
# another terminal
root@u18:~# ps aux |grep malloc
root 6871 1.4 1.2 1175156 104648 pts/0 Sl+ 14:29 0:00 ./malloc
root 6878 0.0 0.0 13144 1124 pts/1 S+ 14:29 0:00 grep --color=auto malloc
root@u18:~# echo 6871 > tasks
root@u18:~# echo 1049600000 > memory.limit_in_bytes
4 Union FS
联合文件系统(unite serveral directories into a single virtual filesystem): 将不同目录挂载到同一个虚拟文件系统下。
容器文件系统

Linux vs Docker 启动
Linux
- 在启动后,首先将rootfs 设置为readonly, 进行一系列检查, 然后将其切换为“readwrite”供用户使用。
Docker 启动
-
初始化时也是将rootfs 以readonly 方式加载并检查,然而接下来利用union mount 的方式将一个readwrite文件系统挂载在readonly 的rootfs 之上;
-
并且允许再次将下层的FS(file system) 设定为readonly 并且向上叠加。
-
这样一组readonly 和一个writeable 的结构构成一个container 的运行时态, 每一个FS 被称作一个FS层。
Docker 写操作
由于镜像具有共享特性,所以对容器可写层的操作需要依赖存储驱动提供的写时复制和用时分配机制,以此来 支持对容器可写层的修改,进而提高对存储和内存资源的利用率。
-
写时复制
- 写时复制,即Copy-on-Write。
- 一个镜像可以被多个容器使用,但是不需要在内存和磁盘上做多个拷贝。
- 在需要对镜像提供的文件进行修改时,该文件会从镜像的文件系统被复制到容器的可写层的文件系统进行修改,而镜像里面的文件不会改变。
- 不同容器对文件的修改都相互独立、互不影响。
-
用时分配
按需分配空间,而非提前分配,即当一个文件被创建出来后,才会分配空间。
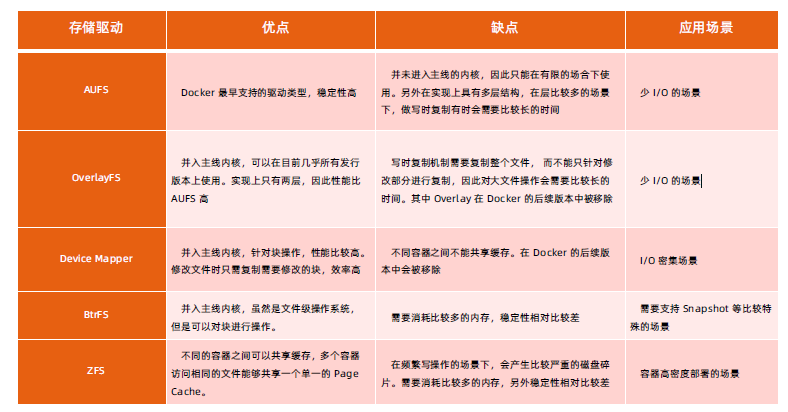
容器存储驱动
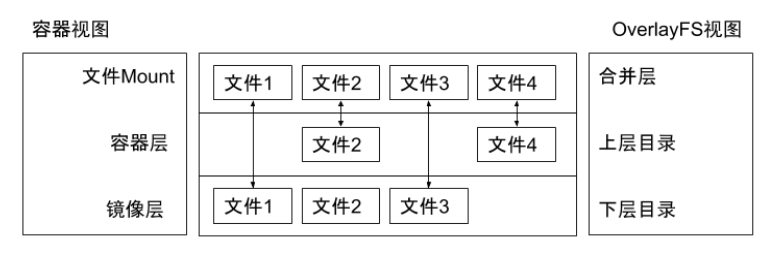
OverlayFS
OverlayFS 也是一种与AUFS 类似的联合文件系统,同样属于文件级的存储驱动,包含了最初的Overlay 和 更新更稳定的overlay2。 Overlay 只有两层:upper 层和lower 层,Lower 层代表镜像层,upper 层代表容器可写层。
example
# 创建upper and lower数据
root@u18:~/test# mkdir upper lower merged
root@u18:~/test# echo "from lower" > lower/in_lower.txt
root@u18:~/test# echo "from upper" > upper/in_upper.txt
root@u18:~/test# echo "from lower" > lower/in_both.txt
root@u18:~/test# echo "from upper" > upper/in_both.txt
root@u18:~/test# tree
.
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
├── upper
│ ├── in_both.txt
│ └── in_upper.txt
4 directories, 4 files
# overlay挂载
root@u18:~/test# mount -t overlay overlay -o lowerdir=`pwd`/lower,upperdir=`pwd`/upper `pwd`/merged
root@u18:~/test# tree
.
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
│ ├── in_both.txt
│ ├── in_lower.txt
│ └── in_upper.txt
├── upper
│ ├── in_both.txt
│ └── in_upper.txt
5 directories, 7 files
# 查看结果
root@u18:~/test# cat merged/in_both.txt
from upper
root@u18:~/test# cat merged/in_lower.txt
from lower
root@u18:~/test# cat merged/in_upper.txt
from upper
OCI容器标准
OCI组织(Open container initiative): 一个致力于定义容器镜像标准和运行时标准的开放式组织。定义了如下标准:
- Image Specification: 镜像规范,定义应用如何打包
- Runtime specification: 容器运行规范,定义如何解压并运行应用
- Distribution Specification: 容器分发规范
Low-Level和High-Level容器运行时
- Low-Level容器运行时:容器是通过Linux nanespace和Cgroups实现的,Namespace能让你为每个容器提供虚拟化系统资源,像是文件系统和网络,Cgroups提供了限制每个容器所能使用的资源的如内存和CPU使用量的方法。在最低级别的运行时中,容器运行时负责为容器建立namespaces和cgroups,然后在其中运行命令,Low-Level容器运行时支持在容器中使用这些操作系统特性。目前来看低级容器运行时有:runc :我们最熟悉也是被广泛使用的容器运行时,代表实现Docker。runv:runV 是一个基于虚拟机管理程序(OCI)的运行时。它通过虚拟化 guest kernel,将容器和主机隔离开来,使得其边界更加清晰,这种方式很容易就能帮助加强主机和容器的安全性。代表实现是kata和Firecracker。runsc:runsc = runc + safety ,典型实现就是谷歌的gvisor,通过拦截应用程序的所有系统调用,提供安全隔离的轻量级容器运行时沙箱。截止目前,貌似并不没有生产环境使用案例。wasm : Wasm的沙箱机制带来的隔离性和安全性,都比Docker做的更好。但是wasm 容器处于草案阶段,距离生产环境尚有很长的一段路。
- High-Level容器运行时:通常情况下,开发人员想要运行一个容器不仅仅需要Low-Level容器运行时提供的这些特性,同时也需要与镜像格式、镜像管理和共享镜像相关的API接口和特性,而这些特性一般由High-Level容器运行时提供。就日常使用来说,Low-Level容器运行时提供的这些特性可能满足不了日常所需,因为这个缘故,唯一会使用Low-Level容器运行时的人是那些实现High-Level容器运行时以及容器工具的开发人员。那些实现Low-Level容器运行时的开发者会说High-Level容器运行时比如containerd和cri-o不像真正的容器运行时,因为从他们的角度来看,他们将容器运行的实现外包给了runc。但是从用户的角度来看,它们只是提供容器功能的单个组件,可以被另一个的实现替换,因此从这个角度将其称为runtime仍然是有意义的。即使containerd和cri-o都使用runc,但是它们是截然不同的项目,支持的特性也是非常不同的。dockershim, containerd 和cri-o都是遵循CRI的容器运行时,我们称他们为高层级运行时(High-level Runtime)。
docker引擎架构
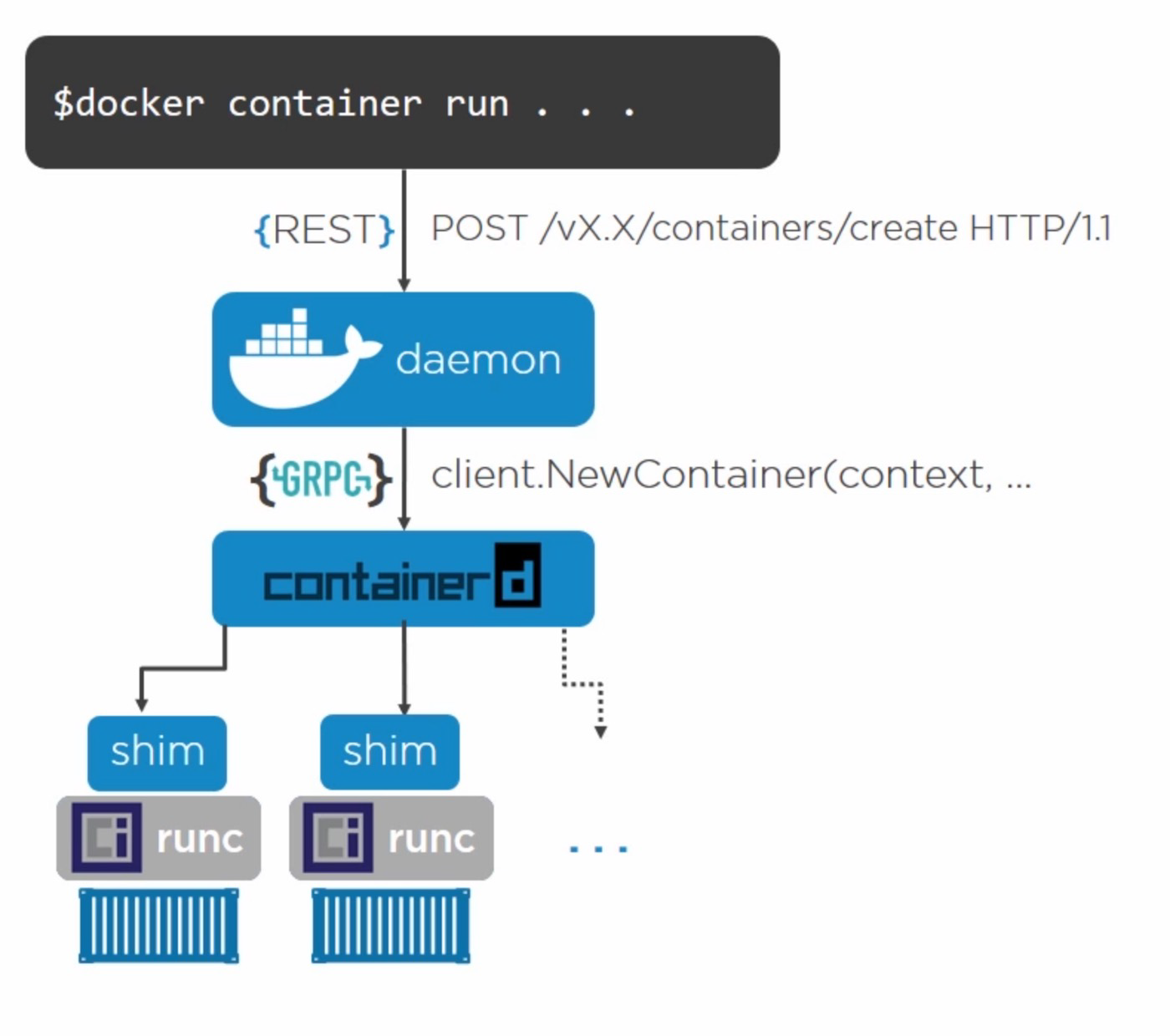
containerd 是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性,containerd 可以负责干下面这些事情:
- 管理容器的生命周期(从创建容器到销毁容器)
- 拉取/推送容器镜像
- 存储管理(管理镜像及容器数据的存储)
- 调用 runc 运行容器(与 runc 等容器运行时交互)
- 管理容器网络接口及网络
-
显然_runc_是只是一个命令行工具,_containerd_是一个长期居住守护进程。
docker-containerd-shim的作用:
- 允许runc在创建&运行容器之后退出
- 用shim作为容器的父进程,而不是直接用containerd作为容器的父进程,是为了防止这种情况:当containerd挂掉的时候,shim还在,因此可以保证容器打开的文件描述符不会被关掉
- 依靠shim来收集&报告容器的退出状态,这样就不需要containerd来wait子进程
因此,使用shim的主要作用,就是将containerd和真实的容器(里的进程)解耦,这是第二点和第三点所描述的。而第一点,为什么要允许runc退出呢? 因为,Go编译出来的二进制文件,默认是静态链接,因此,如果一个机器上起N个容器,那么就会占用M*N的内存,其中M是一个runc所消耗的内存。 但是出于上面描述的原因又不想直接让containerd来做容器的父进程,因此,就需要一个比runc占内存更小的东西来作父进程,也就是shim。
参考: