[TOC]
1.Model Representation
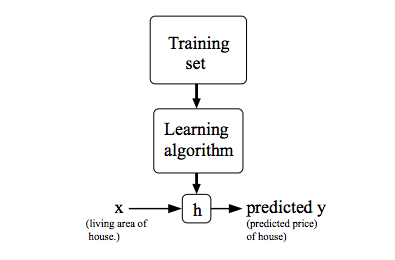
定义:给定一个训练数据集,学习一个函数作为预测器(假设函数hypothesis),这个预测器就是模型。
given a training set, to learn a function h : X → Y so that h(x) is a “good” predictor for the corresponding value of y. this function h is called a hypothesis.
2.Cost Function
损失函数 定义:用来衡量假设函数的准确性。
对给定的输入x,用预测值(h(x)和真实值y的函数f(h(x), y) 计算得,不同的数据和模型有不同的函数。如果预测结果和真实值越接近,则说明模型学习的越好。如下例子:
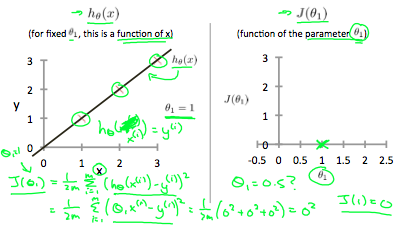
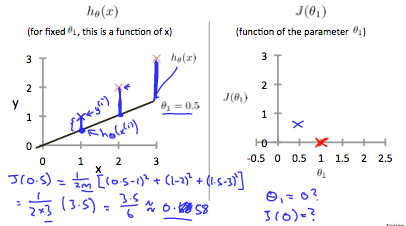
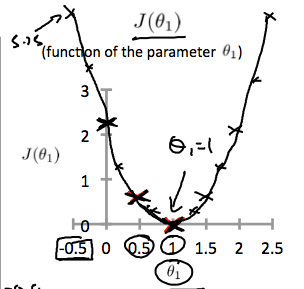
不同的模型参数theta得到不同的模型,对应的损失函数值也不同,通过最小化损失函数来寻找最好的模型。
对于不同的模型,拥有不同的损失函数曲线图,等高线上面的损失值是相等的,虽然模型参数值可能不同。
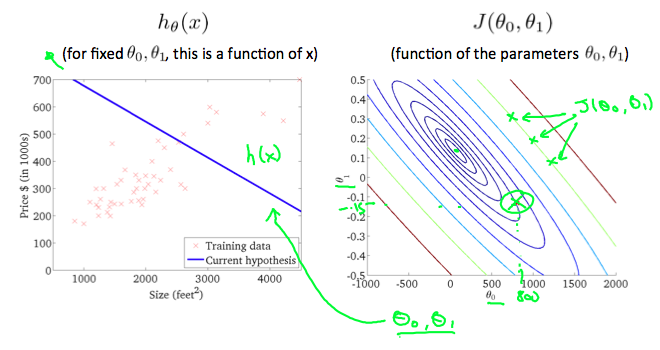
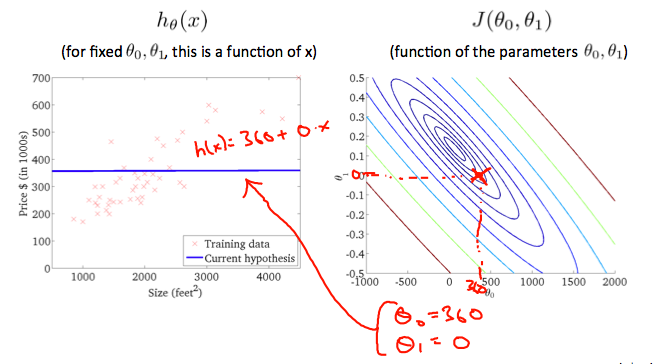
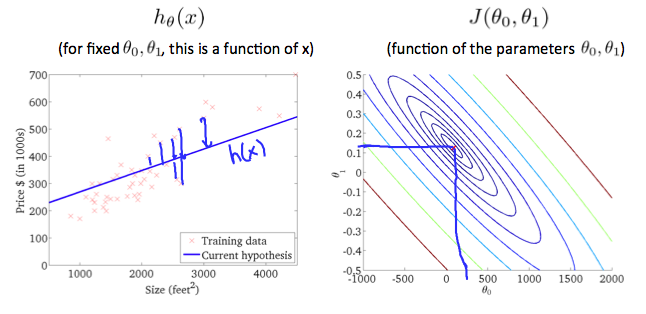
3.Gradient Descent
梯度下降:每个模型有对应的模型参数,损失函数用来衡量模型与数据之间的匹配程度。为了让模型更加的匹配数据,需要对模型参数进行调整,而梯度下降是一种更新模型参数的方法。
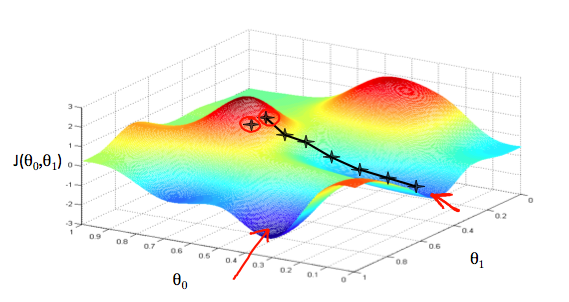
注意:在更新参数的时候,计算偏导数 Partial derivative 的时候,使用的是本轮迭代参数更新之前的参数,而不是前面更新了参数,立马在后面的求偏导数中使用更新的参数计算。

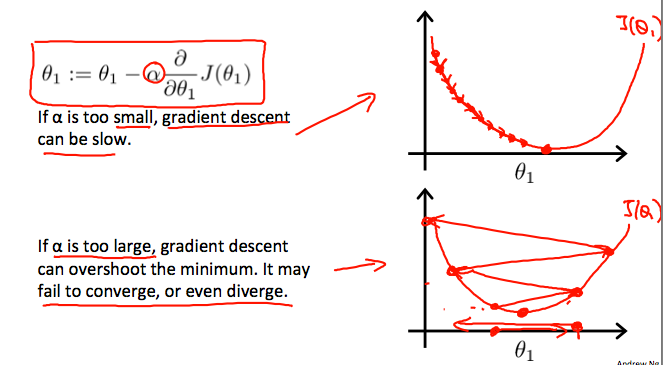
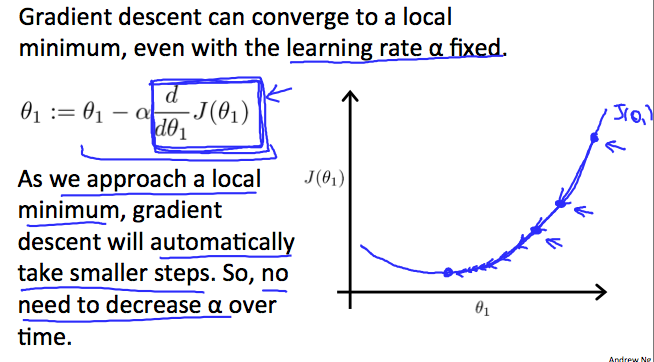
对于学习率的选择:
Gradient Descent For Linear Regression
看公式:
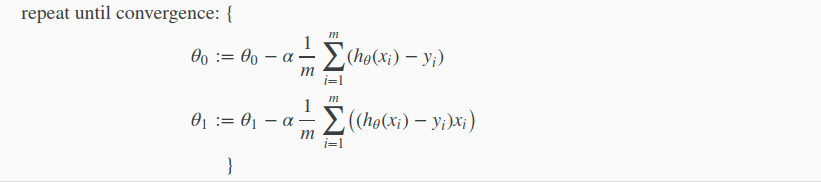
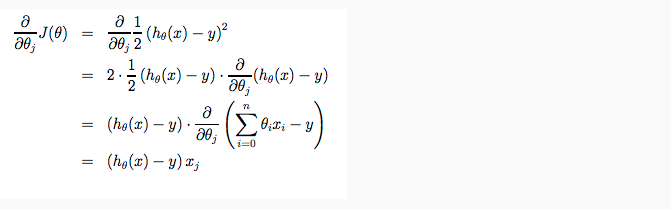
4.Matrix and Vector
Matrix:矩阵是一个二维数组
Vector:只有一列的二维数组

Inverse and Transpose
Transpose:转置

Inverse: 逆矩阵
单位矩阵 = 矩阵A × 逆矩阵inv(A)
example:
% Initialize matrix A
A = [1,2,0;0,5,6;7,0,9]
% Transpose A
A_trans = A'
% Take the inverse of A
A_inv = inv(A)
% What is A^(-1)*A?
A_invA = inv(A)*A
% A =
% 1 2 0
% 0 5 6
% 7 0 9
% A_trans =
% 1 0 7
% 2 5 0
% 0 6 9
% A_inv =
% 0.348837 -0.139535 0.093023
% 0.325581 0.069767 -0.046512
% -0.271318 0.108527 0.038760
% A_invA =
% 1.00000 -0.00000 0.00000
% 0.00000 1.00000 -0.00000
% -0.00000 0.00000 1.00000